Home
Welcome to Ivy's website
Empowering the World with My Data Analysis and Data Engineering Skills

“If you don't produce, you won't thrive - no matter how skilled or talented you are.”
- Cal Newport, Deep Work: Rules for Focused Success in a Distracted World
I am Ivy, a combination of healthcare and data background, am looking for a Data Engineer / Data Analyst position in the UK. Any help will be highly appreciated! I am adept at SQL, Python, and Data Visualisation, I am a certified Azure Data Engineer and GCP Data Engineer, have experience handling large datasets (one published dataset link) and love building data pipelines with Docker and Airflow.
- 3 years, when I studied in a lab, A/B testing to validate my hypothesis
- 2 years, when I worked in a biotech startup, I managed databases, prepared datasets
- 1 year, when I studied Business Analytics, I converted data into business insights
- 2 years, when I self-trained myself, I kept learning data engineering tools
“If you don't produce, you won't thrive - no matter how skilled or talented you are.”
- Cal Newport, Deep Work: Rules for Focused Success in a Distracted World
I am Ivy, a combination of healthcare and data background, am looking for a Data Engineer / Data Analyst position in the UK. Any help will be highly appreciated! I am adept at SQL, Python, and Data Visualisation, I am a certified Azure Data Engineer and GCP Data Engineer, have experience handling large datasets (one published dataset link) and love building data pipelines with Docker and Airflow.
- 3 years, when I studied in a lab, A/B testing to validate my hypothesis
- 2 years, when I worked in a biotech startup, I managed databases, prepared datasets
- 1 year, when I studied Business Analytics, I converted data into business insights
- 2 years, when I self-trained myself, I kept learning data engineering tools
“If you don't produce, you won't thrive - no matter how skilled or talented you are.”
- Cal Newport, Deep Work: Rules for Focused Success in a Distracted World
I am Ivy, a combination of healthcare and data background, am looking for a Data Engineer / Data Analyst position in the UK. Any help will be highly appreciated! I am adept at SQL, Python, and Data Visualisation, I am a certified Azure Data Engineer and GCP Data Engineer, have experience handling large datasets (one published dataset link) and love building data pipelines with Docker and Airflow.
- 3 years, when I studied in a lab, A/B testing to validate my hypothesis
- 2 years, when I worked in a biotech startup, I managed databases, prepared datasets
- 1 year, when I studied Business Analytics, I converted data into business insights
- 2 years, when I self-trained myself, I kept learning data engineering tools
Data Analysis Projects
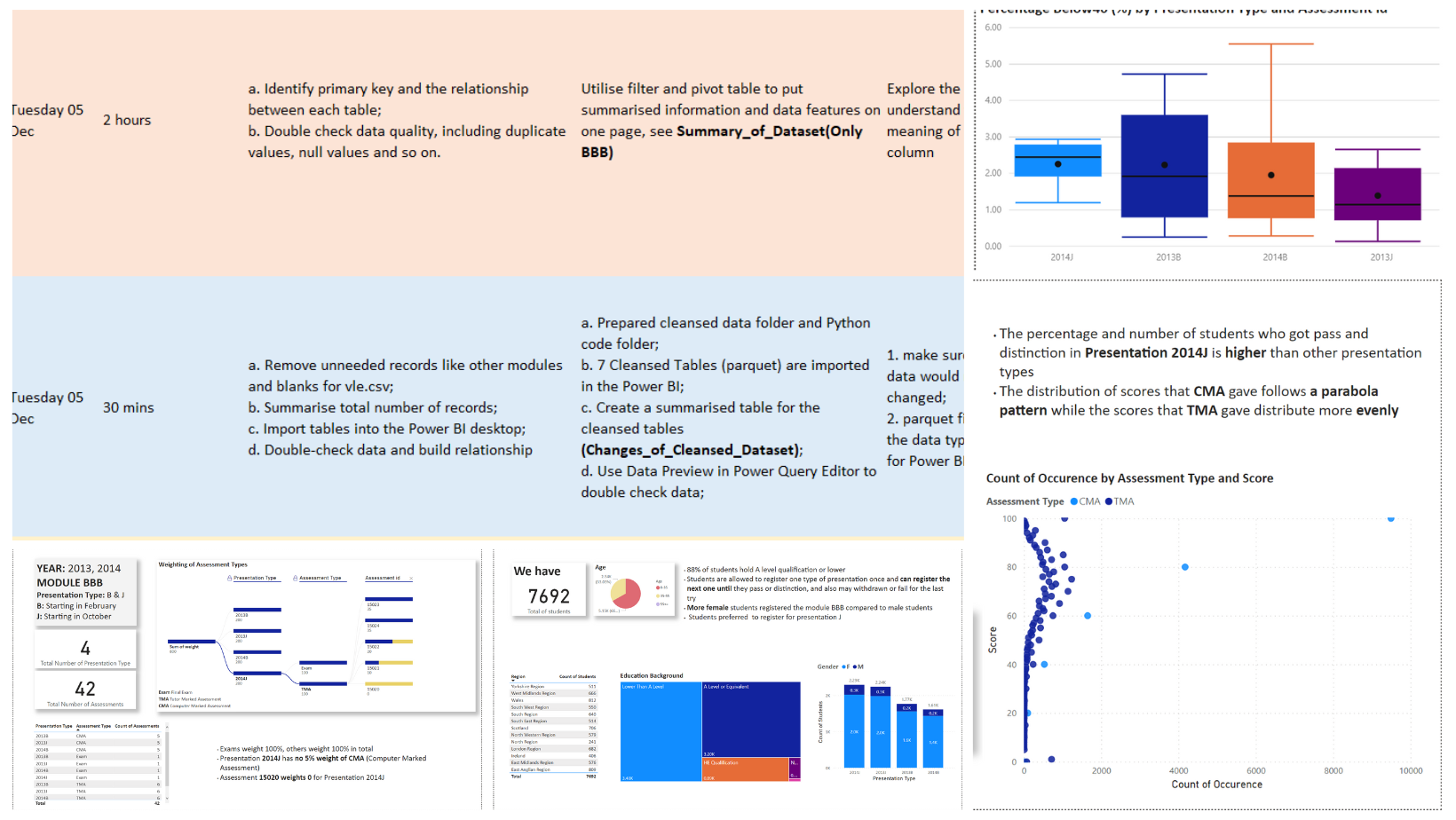
Education-Focused Analysis: How Assessment Types Shape the Final Result
I used Power BI to explore the reasons why the mix and weightings of assessment types shaped the final result
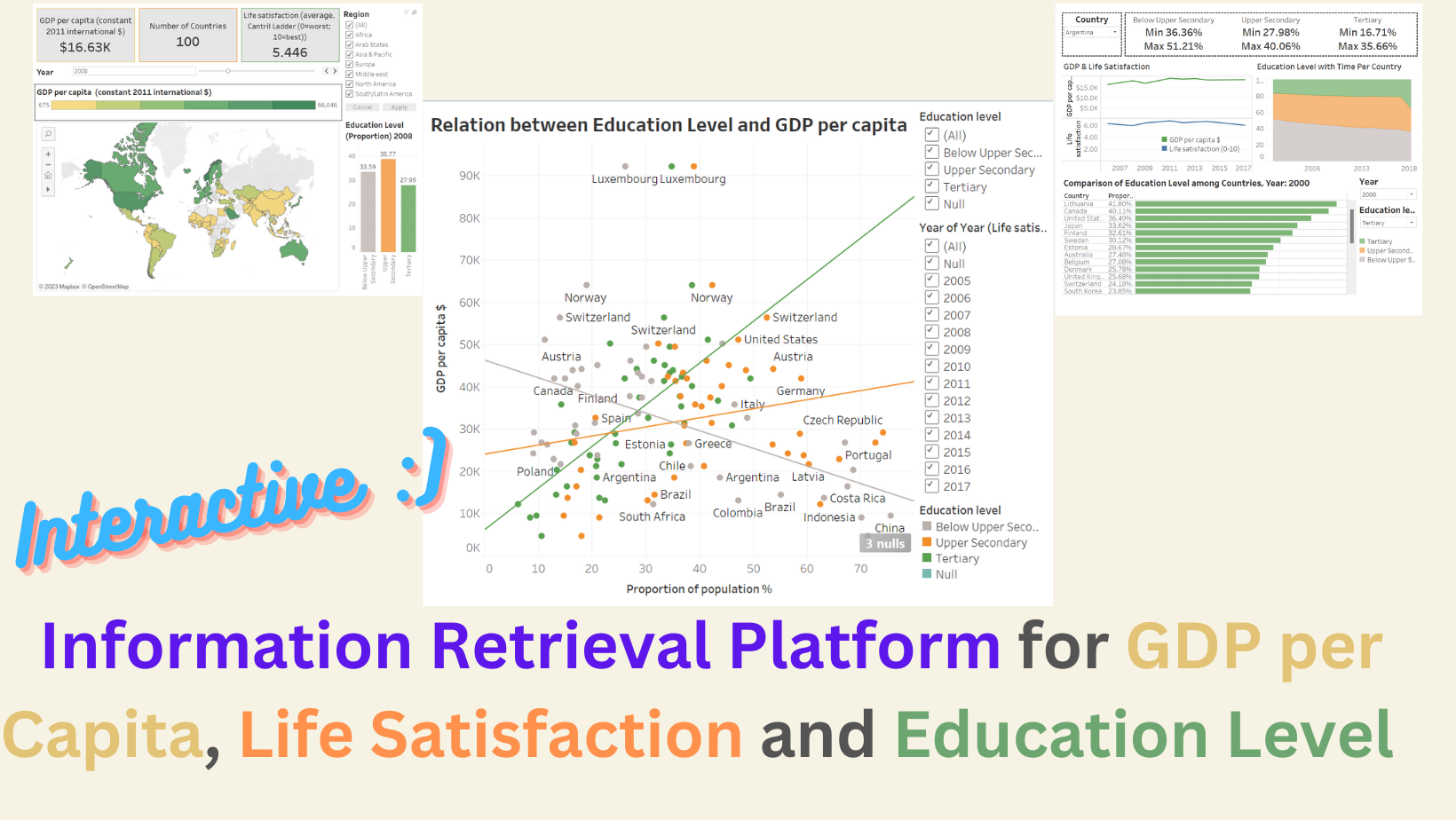
A self-service platform for GDP, Life Satisfaction and Education Level
I used Tableau to build a self-service platform including information about GDP, Life Satisfaction and Education Level
.png)
BT Customer Churn Influencer
I used Power BI to visualise the features of churn customers in BT and used Python and logistic regression to calculate the key churn influencers.
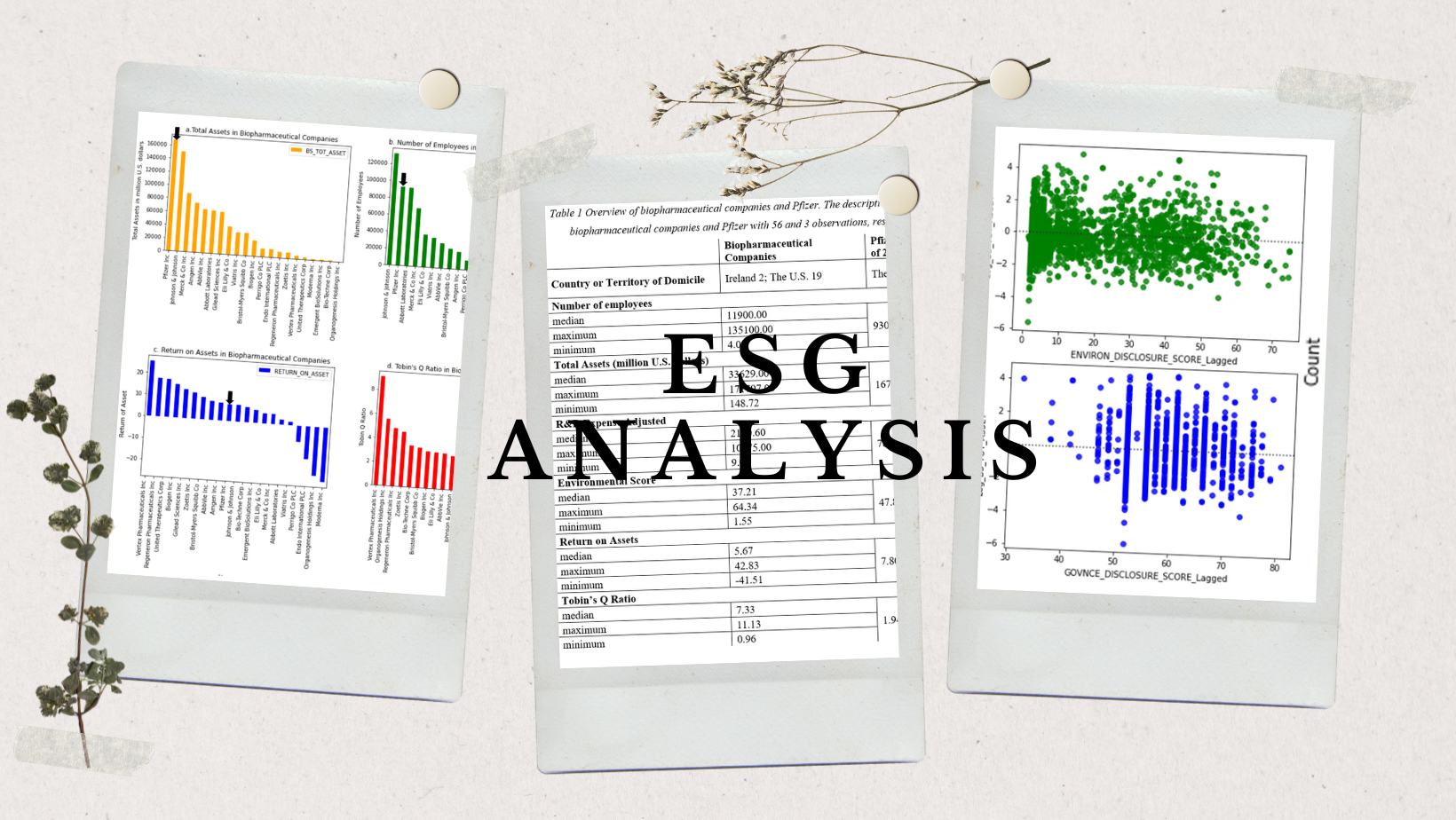
ESG Analysis for Pfizer
I used Python to analyse the position of Pfizer in the pharm industry and linear regression to quantify the relationship between ESG scores and total assets
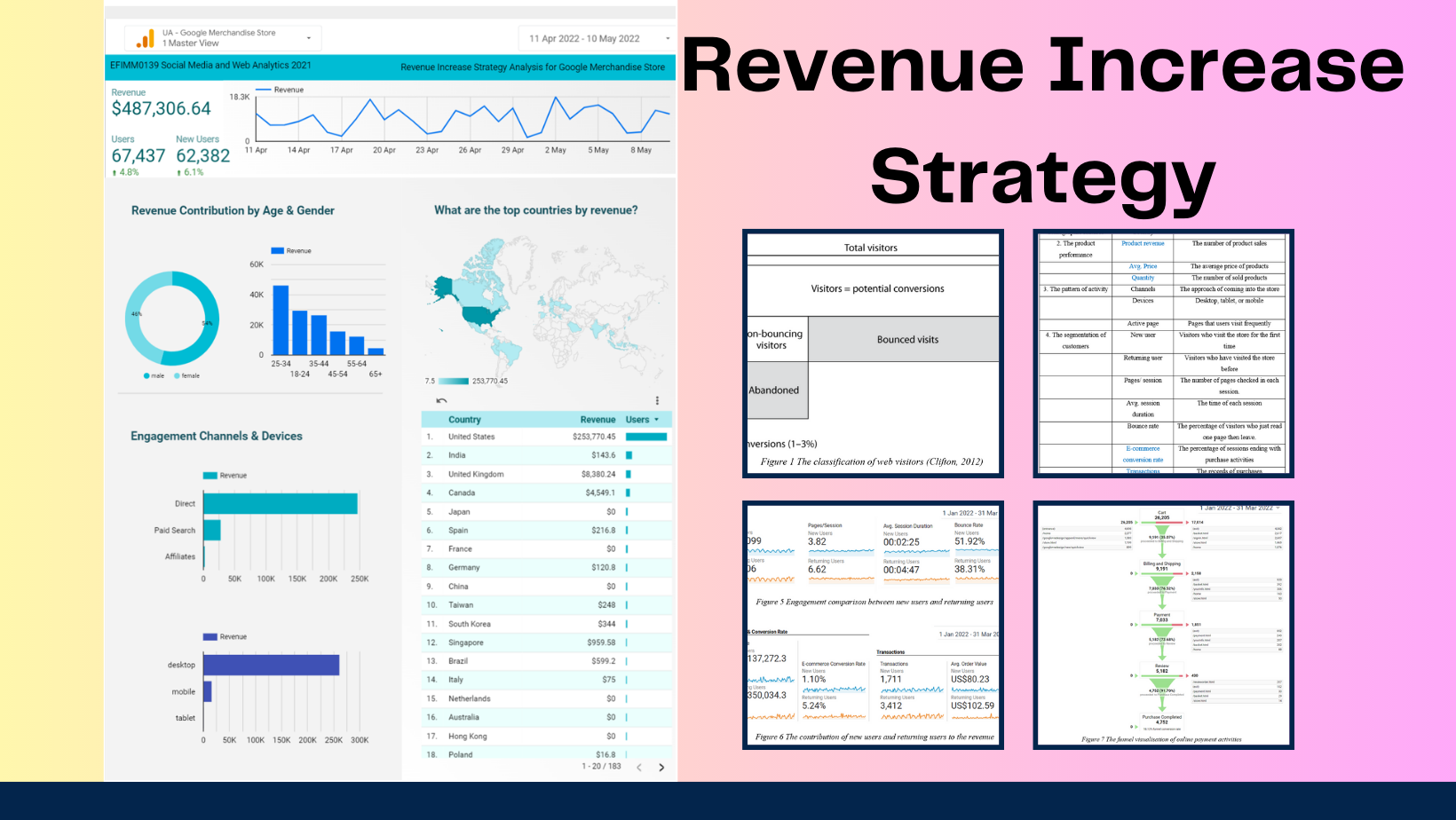
Revenue increase strategy analysis for Google merchandise store
I used Google Analytics and Looker studio to segement customers and analyse customer behaviour
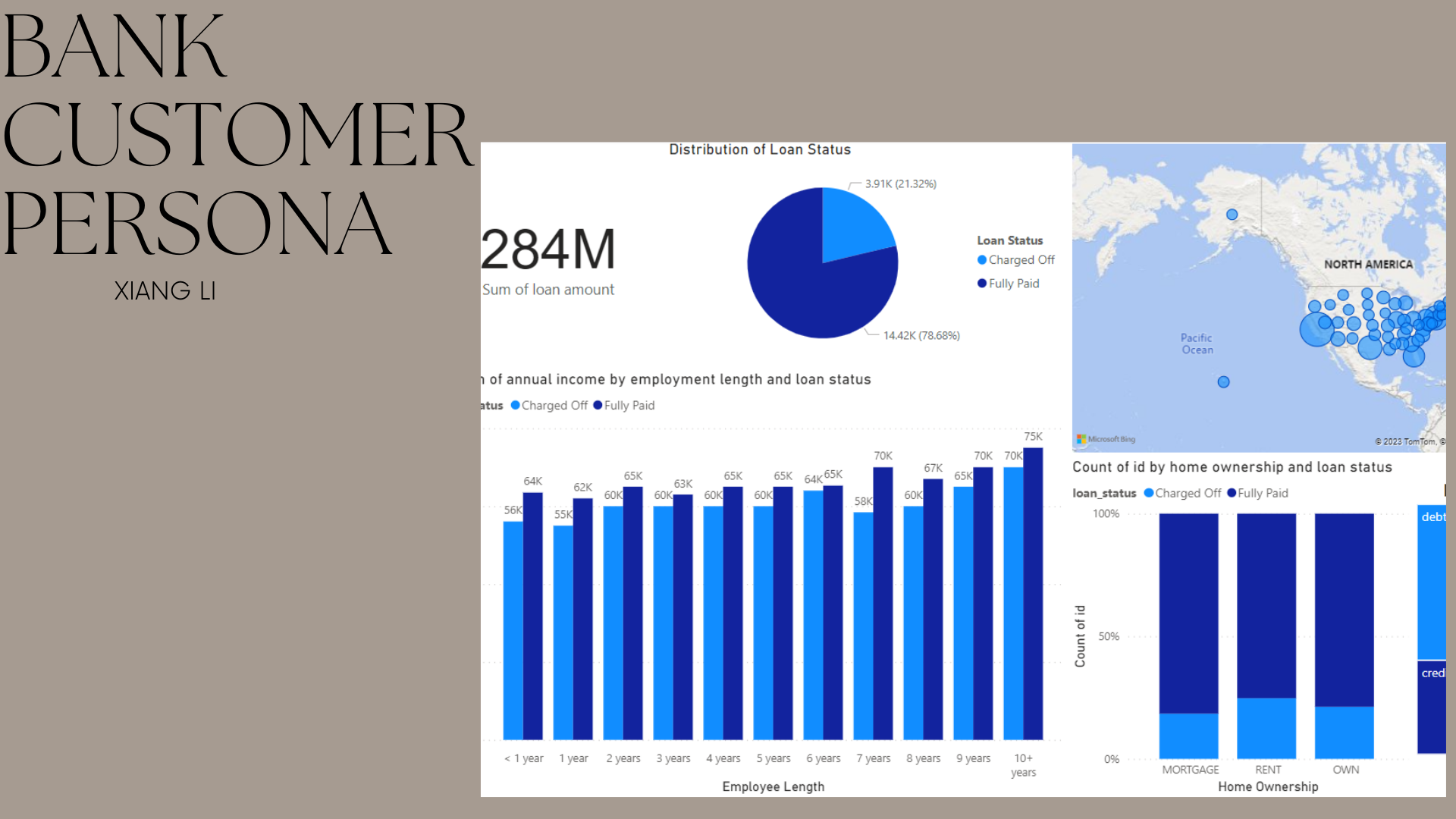
Lloyds Bank Customer Profiling
I used Power BI to profile customers for Lloyds Bank
Database Projects

Data Platform Design for Healthcare Research
I used MySQL to create 11 tables for normalisation of clinical data and genetic data. The work is designed for healthcare research.
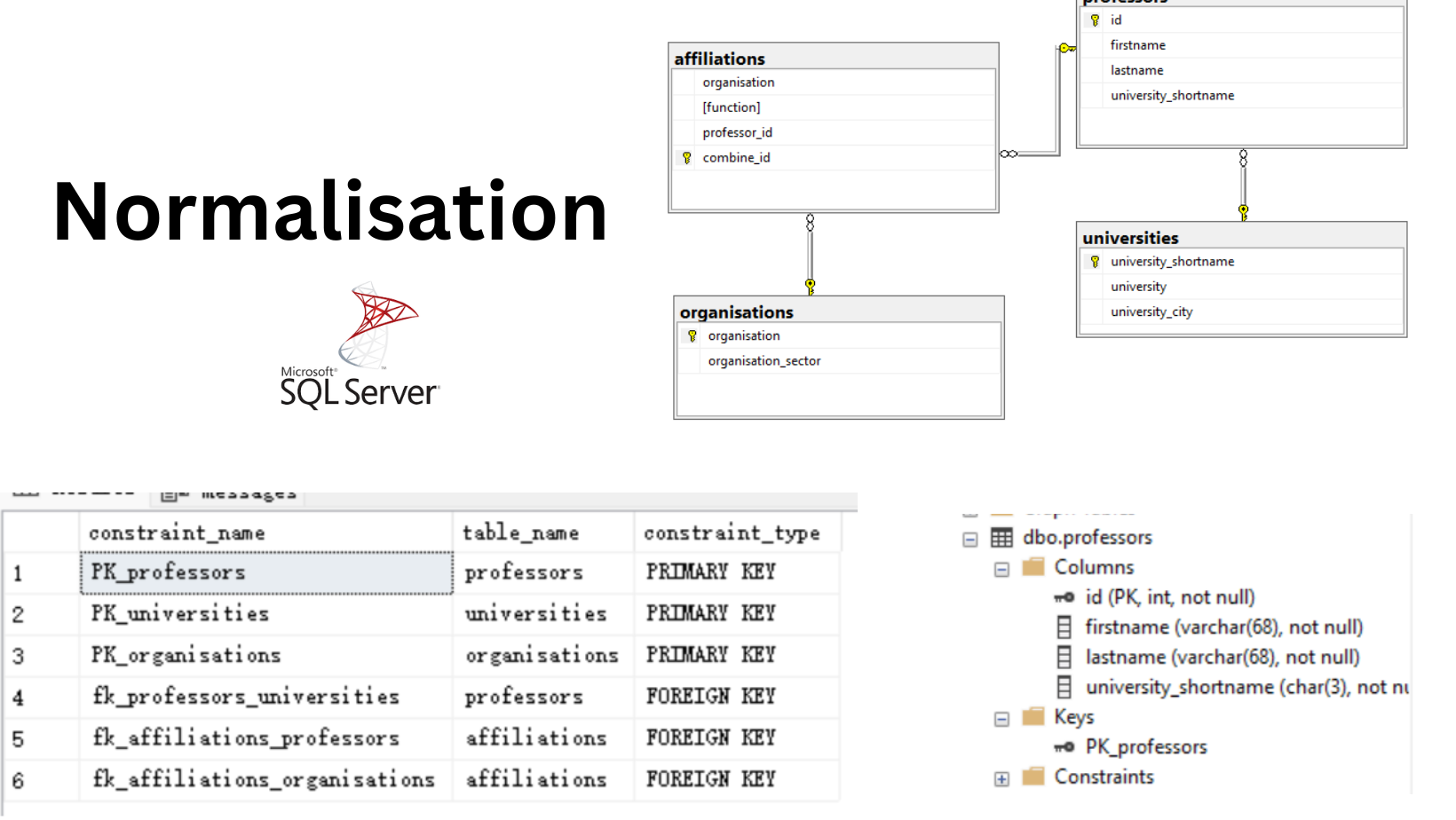
Normalisation for professors in organisations with SQL Server
I used SQL Server to normalise a informative table. The project focused on details, like primary key, surrogate key, relationship, ON DELETE NO ACTION and so on.
Small Projects
.png)
5 Tips to Store an online zip file locally(Python)
In my first blog, I talked about how to create a more structured directory technically, including f-strings, os module, requests and ZipFile library.
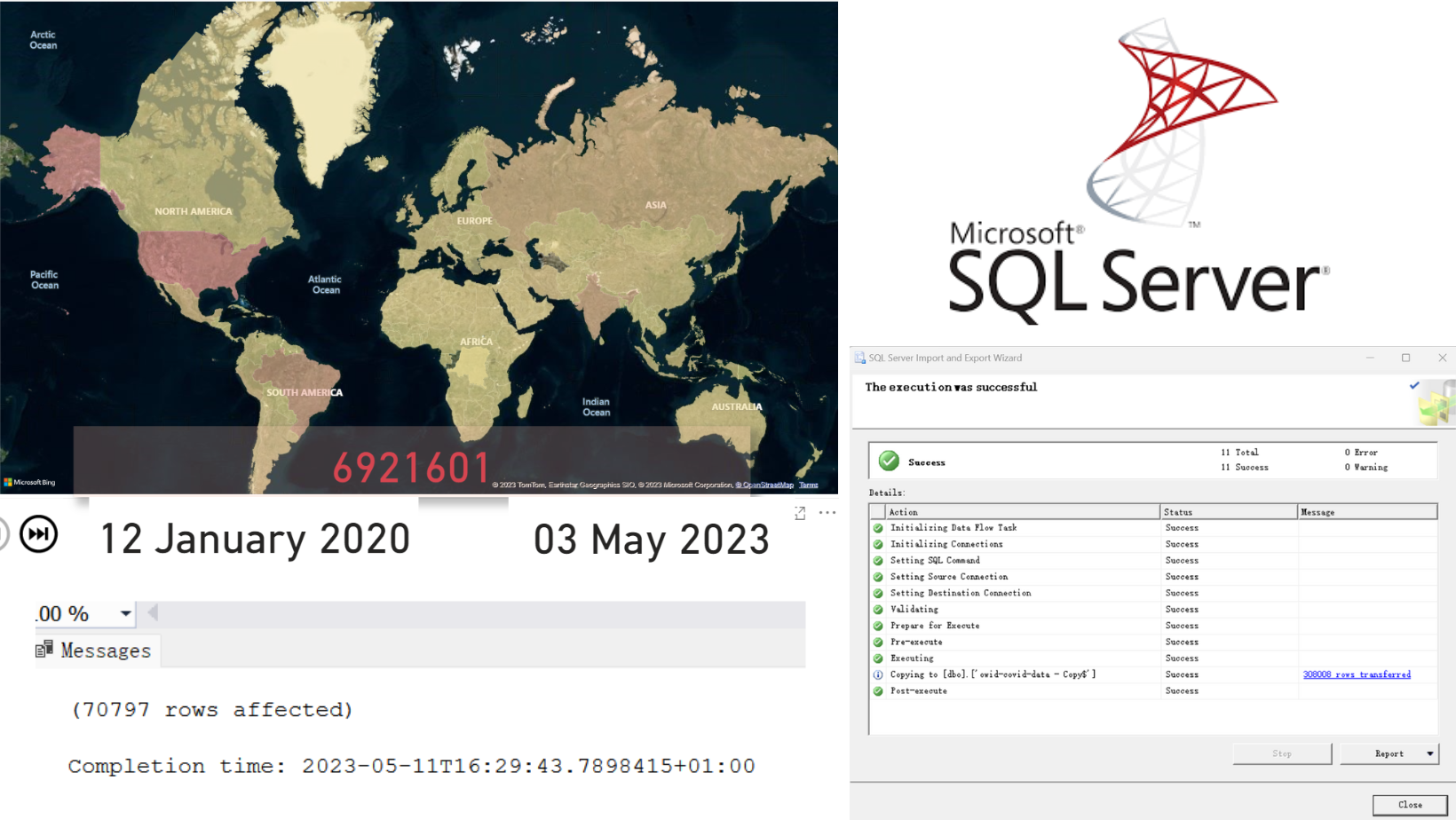
3 Steps to Clean Data in SQL Server
I change my on-premise SQL tool to SQL Server now. I prepared clean data for data visualisation, there are 3 main steps to do.

Import SQLite File into SQL Server with Python and ChatGPT
I learn how to use ChatGPT help achieve the connection between SQLite file and SQL Server with Python。
Mini Blogs for Data Analysis Tools
Around 200 to 300 words for an overview
SQL
Query Language
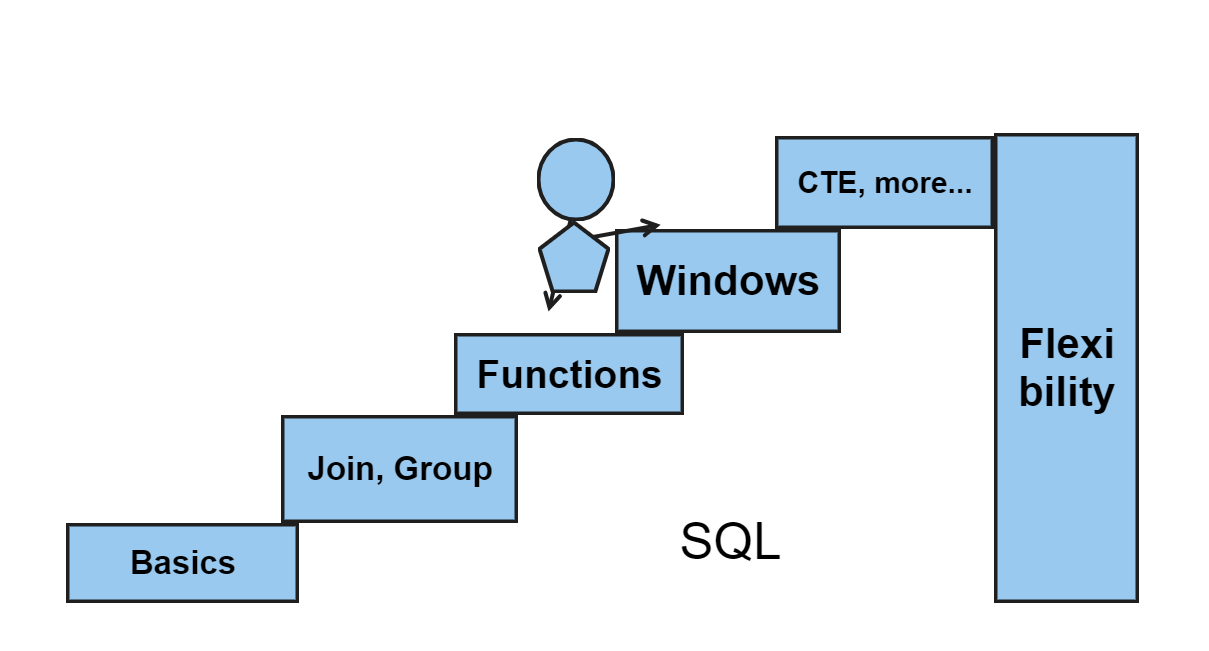
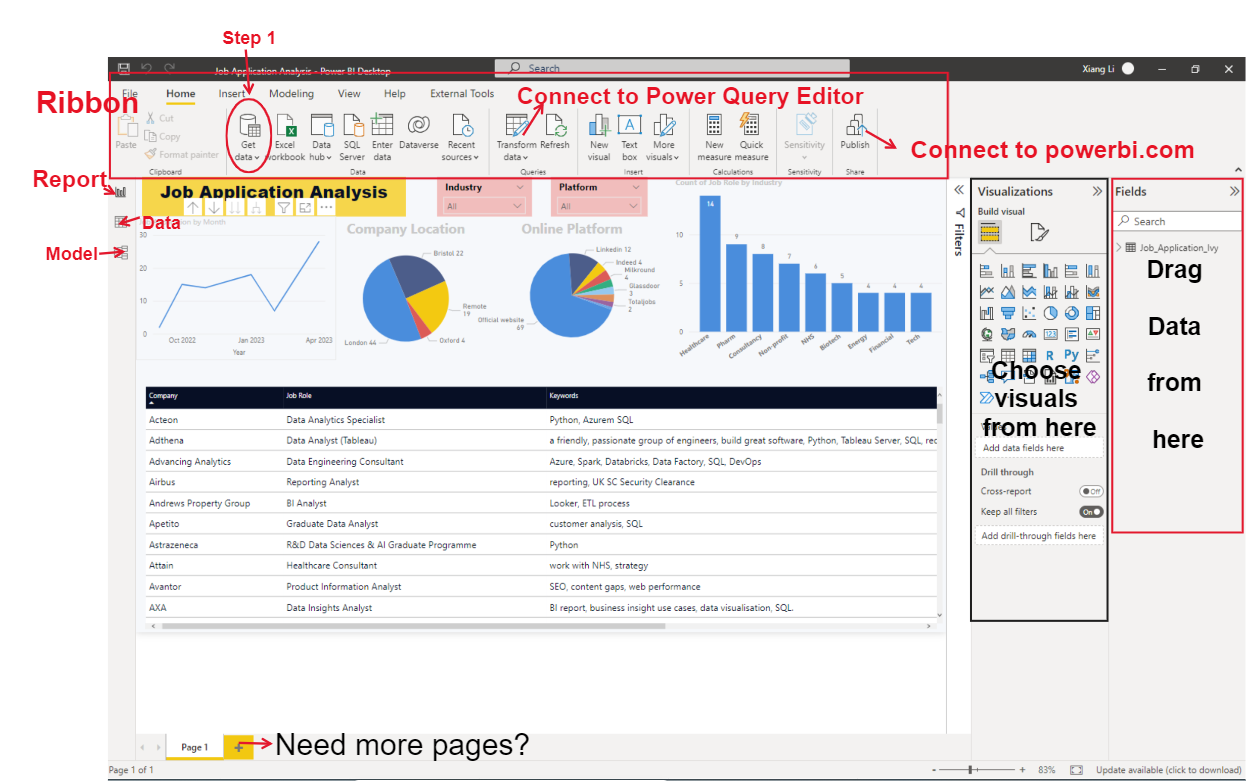
Power BI Desktop
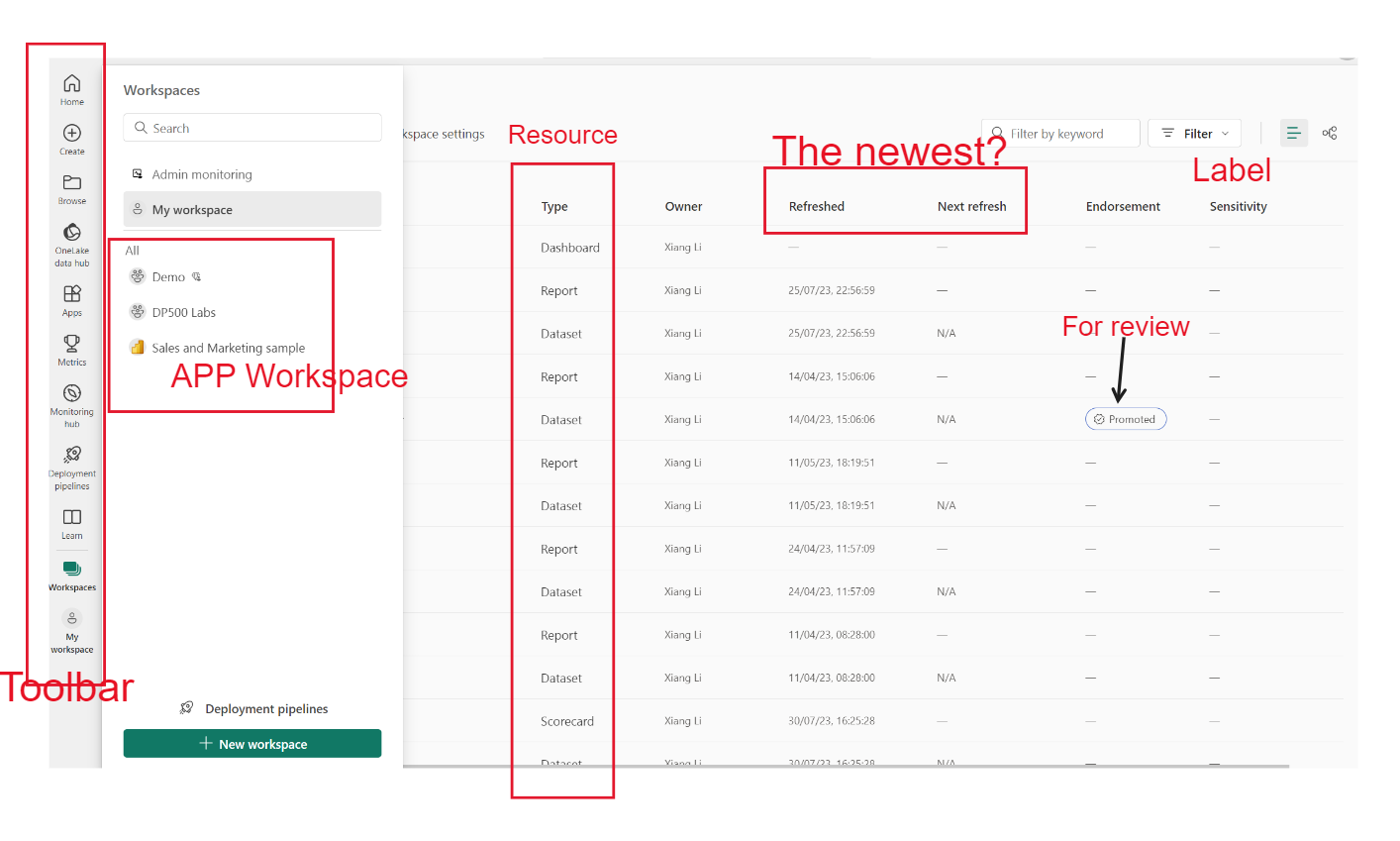
Power BI Service
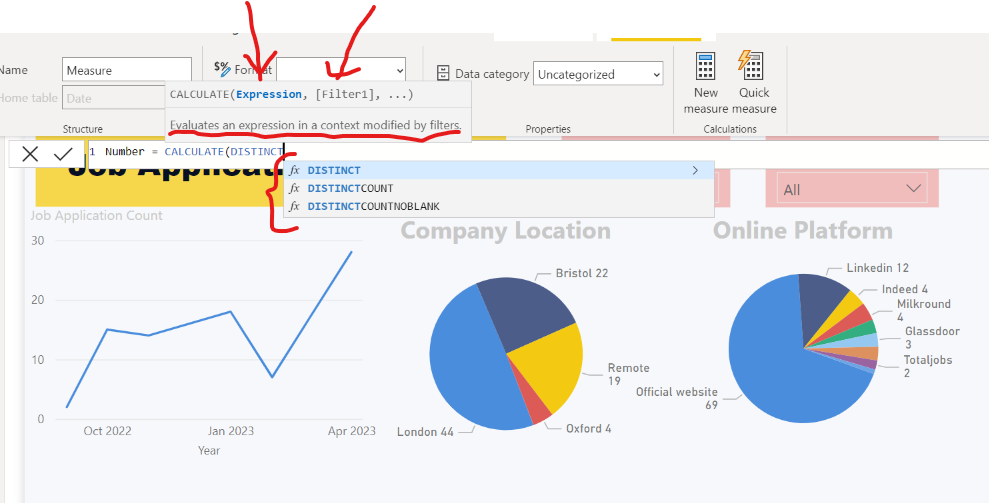
Power BI DAX
Apache Parquet

Python
List Key Tools of Python
Data Structures - Set
Data Structures - Tuple
Data Structures - Arrays Build-in
Data Structures - 2D Arrays (Matrix)
Data Structure - Lists Build-in
Positional and Named Parameters
Class
Debug Methods


Key Points in Computer Science
A short summary for key concepts in CS50
BITS, BYTE
Data Types (C Programming Language)
Command Line
Sort Algorithms
Memory Address - Hexadecimal
Memory Address - Pointer C
Data Structure - Arrays C
Acronyms for Web Development
Certification
Building Expertise through Accumulated Certifications

20/06/2024
Google Cloud Platform Professional Data Engineer
BigQuery
Cloud Storage
Dataflow
CloudSQL
Cloud Composor

11/07/2023
Azure Data Engineer Associate
Data Pipeline
Streaming Analysis
Data Store, Movement and Transformation
Data Encryption
Databricks, Data Factory, Gen2

10/05/2024
Apache Airflow Fundamentals
Orchestration
Scheduling
Dataset
DAGs
Docker
Web Server

19/04/2024
Data Engineering Bootcamp
Data Pipeline
Data Warehousing
Analytics Engineer
Terraform
Bash
Docker
Python

08/08/2024
dbt (Data Build Tool) Bootcamp
Modelling
Materialisation
Documentation
Macro
test
Snowflake

09/04/2023
Power BI Data Analyst Associate
Power BI Desktop
Power BI Service
Prepare Data
Model Data
Visualise and Analyse
Deploy and Maintan

11/06/2023
Azure Enterprise Data Analyst Associate
Azure Synapse Analytics
Power BI
Microsoft Purview
Performance Optimisation

26/03/2023
Azure Fundamentals
Azure
Cloud Data
Cloud Networking
Cloud Security
Cloud Services
Cloud Storage

13/04/2022
Google Data Analytics
Spreadsheets
Tableau
R
SQL

13/01/2023
Data Analyst Professional
SQL
R
Case Study
Presentation

17/03/2023
Data Science Bootcamp
Query databases
Design databases
Data Views
Transactions
Analytical Functions
Big Data

21/01/2023
Lakehouse Fundamentals
- Databricks