Lloyds Bank Customer Profiling
Chapter 1 Project Overview
The event is that Dig Data cooperated with Lloyds Banking Group to provide an opportunity to experience the "real world" business problem.
Background Information
Lloyds Banking Group is launching a new loan product. Prior to the launch, they would like to use historical customer data to:
Understand and summarise the different behaviours or attributes between customers who paid back their loans and customers who did not.
Dataset
The raw data and dictionary can be found on my GitHub.
The published report can be found on my novyPro.
The dataset is based on the American credit risk problem. The dataset contains 18,324 customers with 31 columns who:
Previously held a loan
The status of that loan - did the customer pay back the loan or not:
Customers who paid back are categorised as 'Fully Paid'
Customers who did not pay back their loan are categorised as 'Charged-off'
Other credit and product information that can be used to understand a customer's credit or financial behaviour, like:
emp_length: employment length in years
home_ownership: RENT, OWN, MORTGAGE, OTHER
purpose: a category provided by the borrower for the loan request
etc.
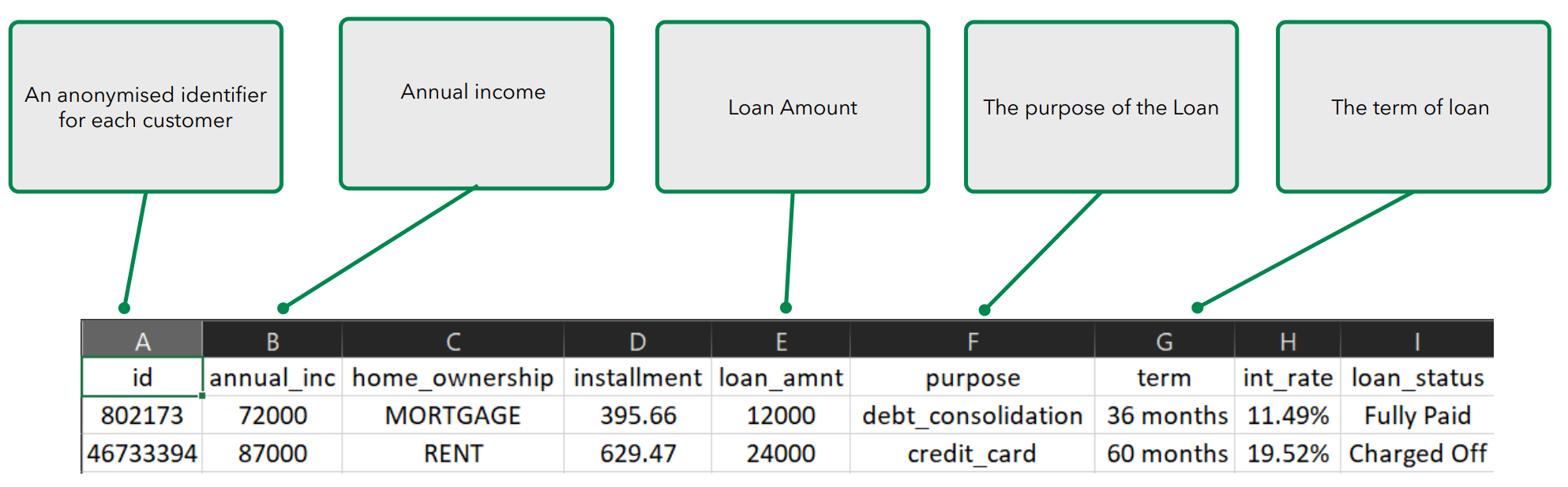
The data for customers on various transactional or credit attributes looks like this:
Data Validation
Step 1: Missing values and duplicate values
Although the dataset contains 31 columns, I chose what I need then validated them against the criteria in the dataset table:
id: 18,324 unique values without missing values. No cleaning is needed.
addr_state: 51 categories without missing values. Add a table including the full name of these abbreviated states to visualise locations.
annual_inc: numeric values without missing values, the range is 3,000 ~ 2,616,000. No cleaning is needed.
emp_length: 11 categories with 1,174 missing values. Need to remove missing values when using this metric.
home_ownership: 5 categories (RENT, MORTGAGE, OWN, ANY, and OTHER) without missing data.
loan_status: 2 categories (Fully Paid, Charged Off) without missing data.
Step 2: Outliers
Validate the skewness of annual income.
mean: 80,176 dollars
median: 65,000 dollars
Considering the mean is around 23% more than the median value, the distribution of annual income is right-skewed. I will use the median value for the annual income metric.
Methodology
This chapter used Power BI to depict features of customers, like the geographical features, the current distribution of loan status, and the distribution of purposes, then explore the relationship between loan status and employment length, income and home ownership.
- the analysis adds a small dataset including U.S. state and territory two-letter abbreviations corresponding to full name.
- the analysis adds a small dataset to confirm the order of employment length.
- the lower left corner deleted the missing value of emp_length.
- ANY and OTHER categories were deleted in the analysis of the relationship between homeownership and loan status.
Perspectives include:
Calculate the total loan amount and check the percentage of "Charged off".
Map the locations of customers.
Visualise the relationship between annual income, employment length and loan status.
Check the relationship between home ownership and loan status.
Have general ideas about the purposes of loans.
Customer Profiling
You can find the Power BI file on my GitHub.
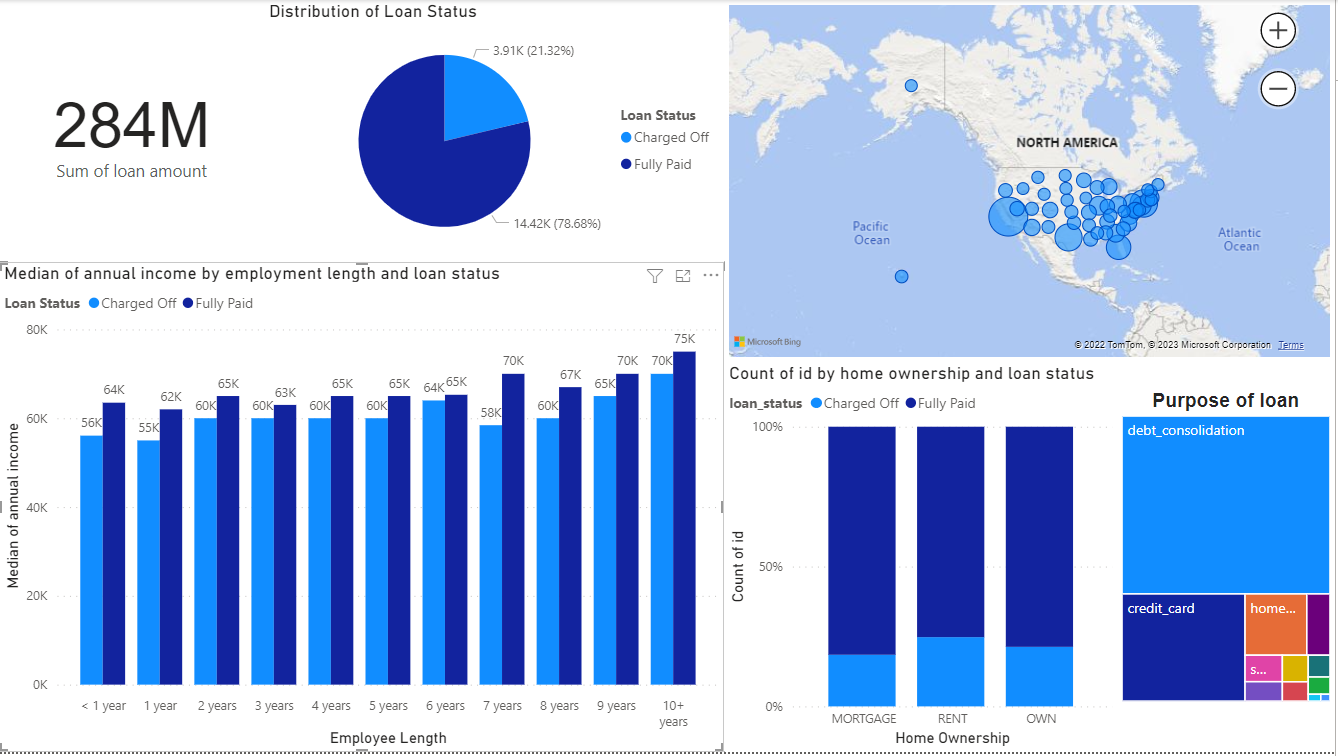
Insights
General ideas
The total loan is 284 million dollars.
14,418 customers have paid back while 3,906 have not.
Location Features
Customers who borrow loans mainly live on the east coast of the U.S.
The total loan amount rented by customers who live in California is extremely high.
Customer Financial Features
Income increases with employee length, and the higher income group is likely to pay back.
Customers who rent their home struggle to pay back.
More than half of customers apply for a loan to consolidate debt; the 2nd purpose is to support credit cards.
My Certificate
