5 Tips to Store an online zip file locally(Python)
I still remember when I met Python for the first time, Dr Higgs gave us a path where we could get the file. I felt stuck when I first saw the unfamiliar format and was too shy to say I did not know it. I sat for around 10 mins without doing anything until Dr Higgs saved me.
So in my first blog, I want to talk about local directory creation and putting files in the right place in the Extract stage. There are several tips that I feel are convenient and I want to share them with you.
folder structure
f-strings
os module
requests HTTP
ZipFile
I got the ideas from DataCamp taught by Stefano Francavilla (ETL in Python)
You can find the complete code demo on my GitHub.
1. folder structure
Considering the original file is zipped, there are two folders for zipped files and unzipped files. As the folder map shows, the data directory is organised by date, for 2023 April, there are two subdirectories, a source path for zipped files, and a raw path for listing CSV files.
2. f-strings
f-strings is one method of formatted strings, it can put expressions of variables in the string literals with curly brackets {}, you can know more about formatted strings and f-strings from RealPython.
I have set my root directory, two paths, and the destination file name (identified with date), and then f-strings can easily combine these variables together into a complete path.

3. os module
os module is a way to manipulate directories, like create, move, read, etc
I have a defined function for creating folders that I mentioned before, like data, 2023April, source, raw
def create_folder_if_not_exists(path):
os.makedirs(os.path.dirname(path), exist_ok=True)My local folder has nothing before
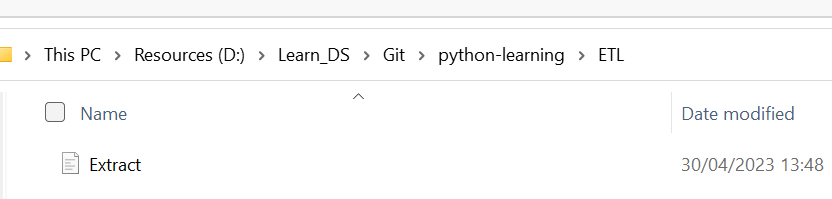
Then I run the following code
create_folder_if_not_exists(source_path)My local folder has a source path
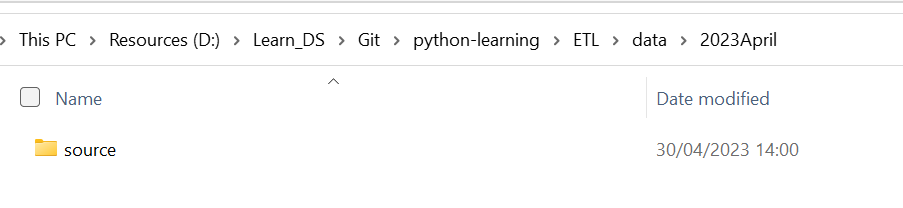
Then I run the following code for creating a raw path
create_folder_if_not_exists(raw_path)My local folder has a raw folder
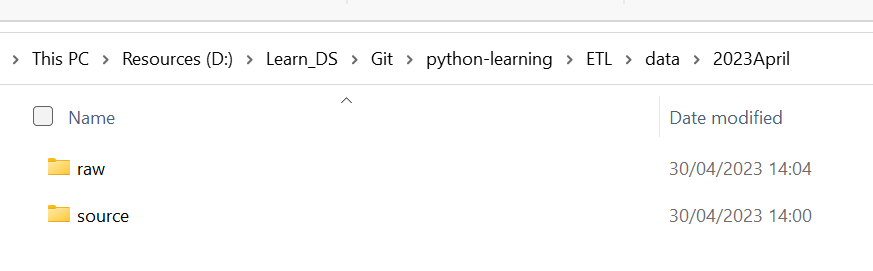
4. requests HTTP library
It is a straightforward way to get data from a URL, you can find more introduction in the Real Python.
As the blog mainly talks about local directory settings, I would not speak a lot about requests, you can just how to use get
#source headers or content and store them to the 'response'
response = requests.get('URL')Then you can write the content in the source path, wb for binary files (non-textual data, like zipped files)
#write content into source_path
with open(source_path, "wb") as source_file:
source_file.write(response.content)5. ZipFile
Before using data, unzipping files into CSV files is a must-do. ZipFile like the Bandizip application, lists all files included with namelist()
Do you remember that our files are stored in the source folders now and still is zipped? :)
We need to extract files and then store them in the raw path.
The code is
with ZipFile(source_path, mode="r") as f:
# Get the list of files and print it
file_names = f.namelist()
print(file_names)
# Extract the csv files with for loop
for file_name in file_names:
csv_file_path = f.extract(file_name, path=raw_path)I am excited to show the final results. Currently, these files stay in the right place now and are ready for the next blog. :)


Okay, these are what I want to tell you in my first blog and they are also the steps of extracting data from a URL. Let me just recap what has been discussed so far.
The purpose of the blog is to store online data locally.
The folder structure is designed in advance, it is divided into a source path for zipped files and a raw path for unzipped files.
The f-strings method is a tip to construct a path in an easy way.
The os module creates local folders with code rather than right-clicking.
The request library gets data and then we can write it into the source path.
The ZipFile library unzips files and stores them in the raw path.